

우리가 흔히 카카오톡, 페이스북, 트위터와 같은 곳에서 링크를 붙여넣어서 공유할때 카드형식의 미리보기를 보여준다.
대표적으로 페이스북의 예로 페이스북은 open graph라는 <meta property="og: title" content="SEO Preview block">이런 형식으로 meta 태그를 입력해 넣으면 페이스북 내부에서 공유할때 이 데이터를 가지고 Preview Card를 만들어서 보여준다.
노션에서 이 기능을 많이 사용했는데 Medium 같은 아티클 플랫폼에서도 많이 사용하는 모습이 보였다. 그래서 내 블로그에서도 도입하고싶었는데 왜? 꼭 도입해야할까? 고민을 해봤다 도입하는데 시간도 걸리고 만만하지 않은 작업 같았기 때문이다.
SEO Preview Block을 도입하기로한 이유를 곰곰히 생각해보았다.
글을 읽는 사람 입장에서
- 저자가 등록한 링크에 대해서 신뢰감있는 링크라는 것을 인지 시켜줄 수 있다.
- 해당 링크에 대해서 미리 정보를 얻어서 간략한 정보를 통해 이미 알고있는 내용의 포스팅인지 판단할 수 있다.
그럼 어떻게 구현할 것인가? 렛츠기릿 🤟
단순하게 링크정보를 받으면 해당 링크 내부의 meta data에서 해당 정보들만 가져와서 사용하면 되겠다.
필요한 정보들
- Title
- url
- description
- favicon
- thumbnail
그러면 이 정보들을 어떻게 가져올까 고민을 해봤다. 이 정보를 가공해서 나한태 제공해줄 API 가 필요한 것이다. 가공도 내가 원하는 정보들로… 🤔
그럼 API 서버를 제작해봐야겠다.
API 서버에서 수행해야할 기능
원하는 데이터를 가져와 가공후 보내줘야 한다. 그러면 크롤링하는 기능을 구현하면 된다. 크롤링을 도와주는 라이브러리 들은 많다 베이스는 JS 라이브러리로 선택… (전 JS 밖에 몰라요 😭)
1. Cheerio
Cheerio는 마크 업을 구문 분석하고 데이터 구조를 순회 / 조작하기위한 API를 제공합니다. 웹 브라우저처럼 결과를 해석하지 않습니다. 특히 시각적 렌더링을 생성하거나 CSS를 적용하거나 외부 리소스를 로드하거나 JavaScript를 실행하지 않습니다. 기능이 필요한 경우 PhantomJS 또는 JSDom 과 같은 프로젝트를 고려해야합니다.
2. osmosis
검색속도, 파싱속도, JQuery, Cheerio or JSDom과 같은 큰 종속성이 없다고 장점으로 내새움
이렇게 찾아보는데 라이브러리들이 대부분 element만 조작해서 데이터를 가져오는 방식이어서 Headless 같은 JS에서 렌더링하는 방식은 불안정한 요소가있었다. 어느 페이지에서나 SPA 같은 환경에서도 동일한 데이터를 가져올 수 있어야 했기때문에 Puppeteer를 선택해서 제작하게되었다.
문제 발생
API 로 받은 링크만 사용한다면? 내가 아는 한, FrontEnd에서 해당 작업에는 오류가 필연적으로 생긴다. CORS 오류가 발생하기 때문이다.
그래서 해당 문제를 내가 참고하는 노션(notion) 서비스에서는 어떻게 구현하나 살펴보았다. 노션에서는 해당 링크의 데이터를 자기 서버에 저장하고 그 이미지를 요청하는 방식으로 변경해서 구현했다.
그러면 CORS 오류가 날 수 있는 image 링크들에 대해서는 서버에 직접 이미지를 저장하고 그 저장한 이미지의 링크를 보내주는 방식으로 구현 방향을 변경하였다.
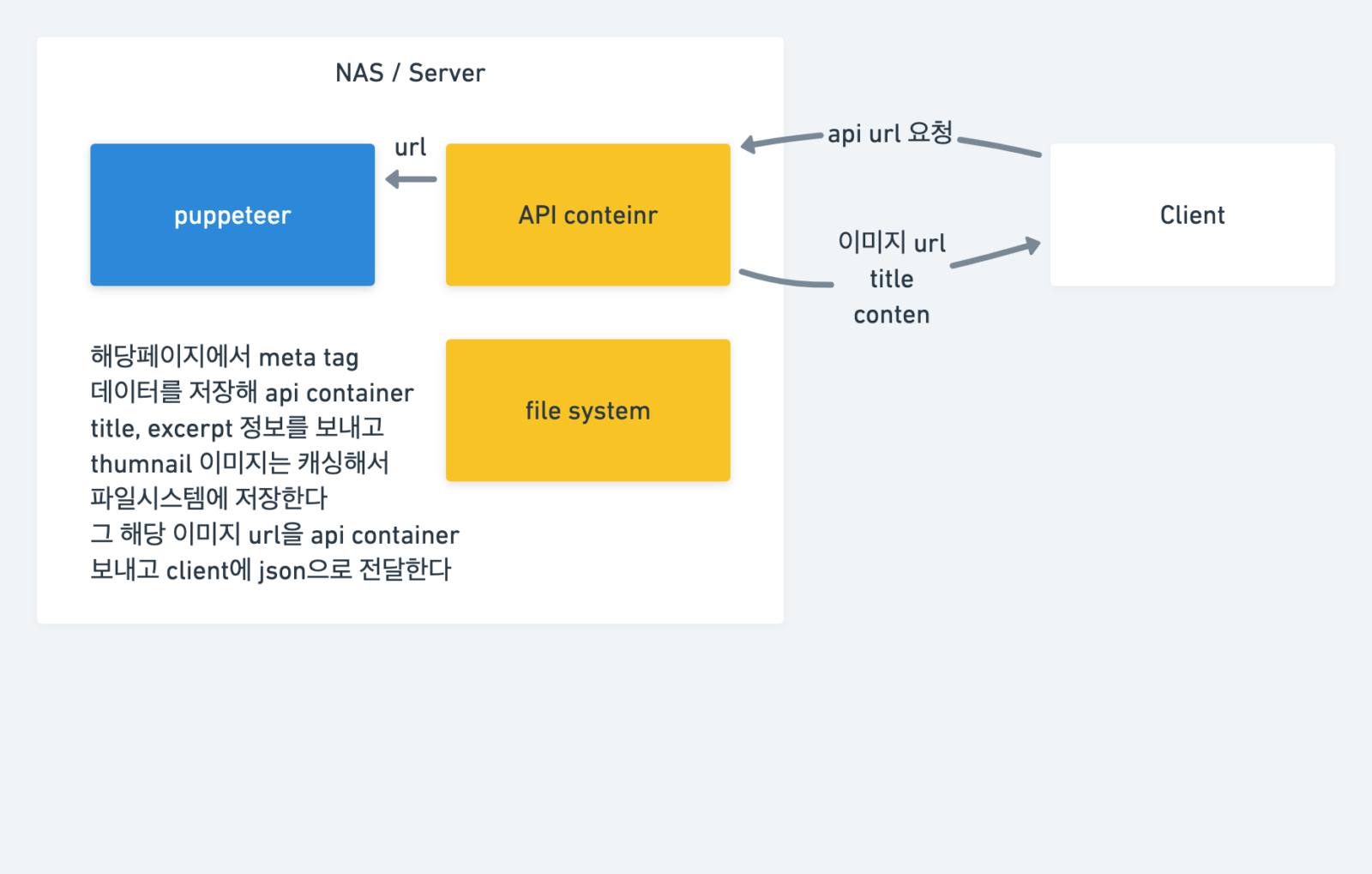
이미지로 정리해보았다. 처음에 SEO Preview Block 만들려했을때 생각했던 것 만큼의 작업량 가지고 제작할 수 없을꺼같다는 느낌을 받았다.
그런데 이렇게 구성하면 매번 요청마다 크롤링하는 무거운 작업을 해야한다. 크롤링을 했던 URL요청의 작업이라면 데이터를 저장해뒀다가 해당 객체 데이터만 전달 해주면 되는 것이다.
크롤링했던 작업인지 체크하는 작업을 하는 것을 정리
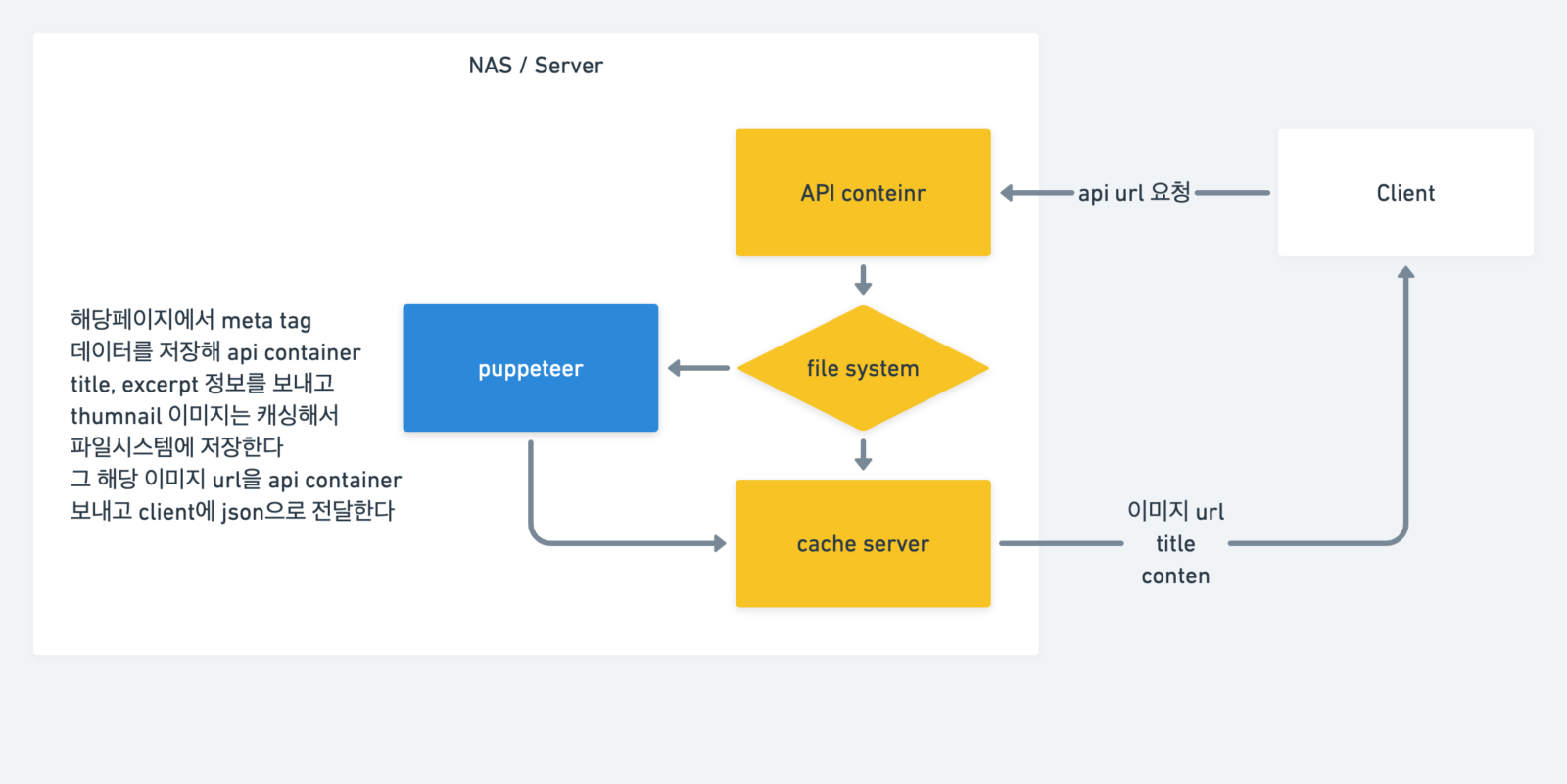
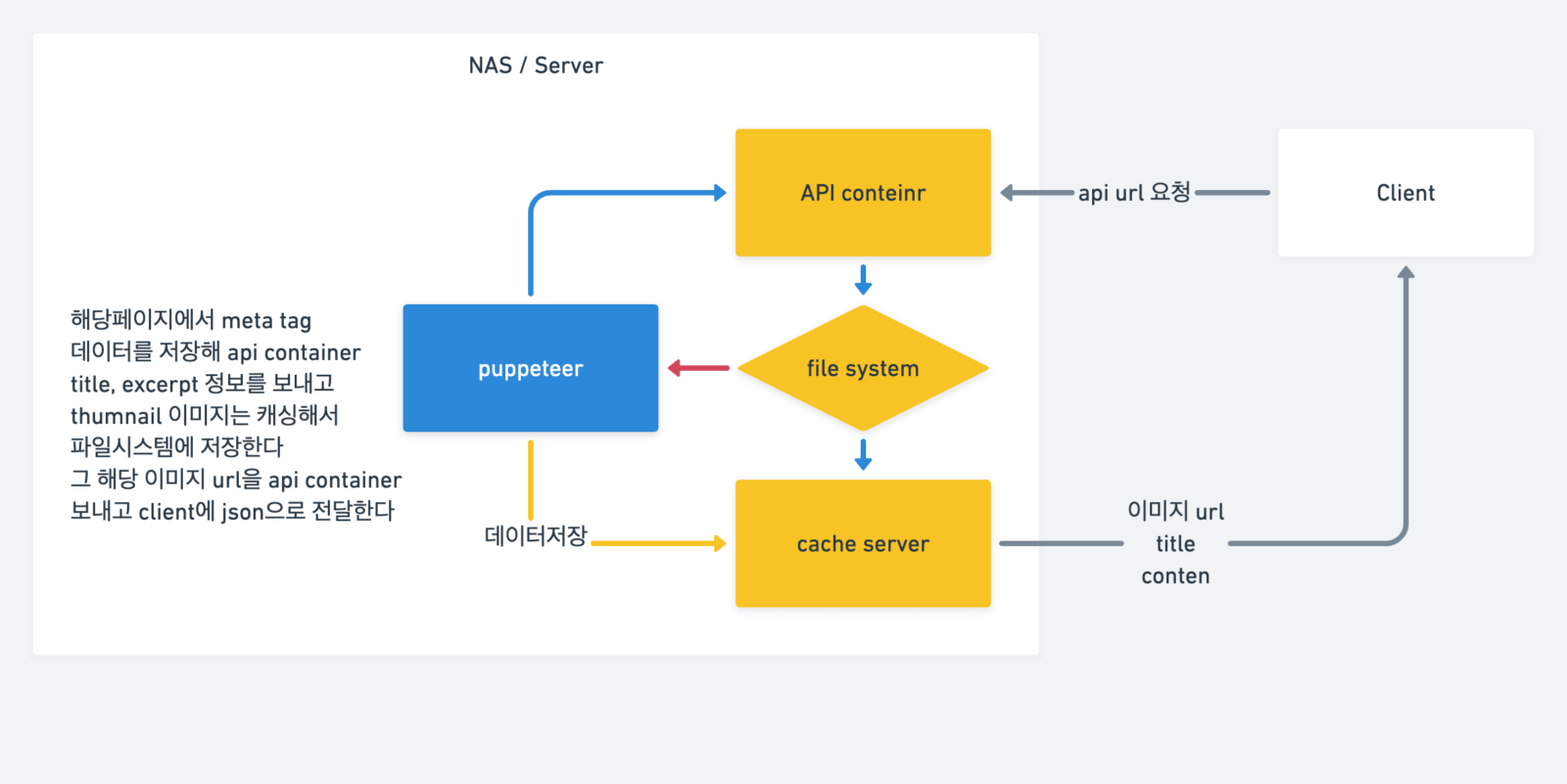
프론트엔드에서 어떻게하면 최적의 환경을 만들 수 있을까 고민해봤다.
SEO Preview 같은 데이터는 바뀔일이 별로없다. 그러면 항상 API 서버에 요청을 해야할까?
프론트엔드에서 Gatsby 를 사용하고있는데 Gatsby에서는 쿼리나 API 를 통해서 받은 데이터를 로컬로 캐싱하는 방법을 소개하고있다. 이 부분을 활용해서 해당 API 를 일회성으로 만들고 요청 받은 데이터를 캐싱하고 빌드하는 방법으로 구성해보면 좋을 것같다.
일단 위 프로세스를 구현해야한다. 위 프로세스가 만들어지고 변경하지 않아도 되니까 한꺼번에 하려하지 말고 제작하자!
API 컨테이너는 NodeJS 기반으로 구성했고 작업은 완료하였다.
NodeJS 에서 Express.js 를 이용하여 API 를 통해서 http://localhost:port/seo/?url='crawler url'을 받아서 메타 데이터중 og의 내용들을 json 형태로 Response 하게 만들었다.
중간 v1.0.0 저장소